Server Migration - технология, позволяющая организовать отказоустойчивое решение с защитой от потери сервиса при потере одного из хостов кластера. Управляемый сервер со всеми приложениями и сервисами поднимается на новом хосте. Решение особенно эффективно для singleton-сервисов.
Моё окружение.
Host 1: 172.16.1.1 hostname: sms_a
Host 2: 172.16.1.2 hostname: sms_b
VIP : 172.16.1.3
Weblogic Server 12.1.2
Oracle Linux 6.4
1.Настройки ОС.
1.1 Для пользователя oracle обновить CLASSPATH на обоих хостах.1.2 Добавить пользователю oracle возможность запускать утилиты с правами суперпользователя. Для этого на обоих хостах редактируется файл /etc/sudoersexport MW_HOME=/opt/oracle/middleware/Oracle_WL
PATH=$PATH:$MW_HOME/user_projects/domains/sms_domain/nodemanager:$MW_HOME/user_projects/domains/sms_domain/bin/server_migration:$MW_HOME/Oracle_WL/wlserver/common/bin
export PATH
oracle ALL=NOPASSWD: /sbin/ifconfig,/sbin/arping,$DOMAIN_HOME/bin/server_migration/wlsifconfig.sh
Если этого не сделать, в логах nodemanager-а можно наблюдать вот такие сообщения:
<Jul 16, 2014 11:41:19 AM MSK> <WARNING> <sudo: sorry, you must have a tty to run sudo>
<Jul 16, 2014 11:41:19 AM MSK> <WARNING> <Failed to remove 172.16.5.231 netmask from eth0:1.>
<Jul 16, 2014 11:41:19 AM MSK> <WARNING> <Exception while executing 'PostStop' ExecutableCallbacks>
java.io.IOException: Exception while executing 'PostStop' ExecutableCallbacks
at weblogic.nodemanager.server.WLSProcess$MultiExecuteCallbackHook.execute(WLSProcess.java:290)
at weblogic.nodemanager.server.WLSProcess.executePostStopHooks(WLSProcess.java:239)
at weblogic.nodemanager.server.WLSProcess.waitForProcessDeath(WLSProcess.java:205)
at weblogic.nodemanager.server.ServerMonitor.runMonitor(ServerMonitor.java:298)
at weblogic.nodemanager.server.ServerMonitor.run(ServerMonitor.java:254)
at java.lang.Thread.run(Thread.java:745)
Caused by: weblogic.nodemanager.util.MultiException:
В Linux обычно запрещено выполнение команд вида
ssh oracle@servername sudo ifconfigОни не безопасны, так как передают пароль в открытом виде. Такая команда завершится с ошибкой.
sudo: sorry, you must have a tty to run sudoВообще говоря, при подключении по ssh у пользователя нет tty не только для sudo:
ssh oracle@servername tty1.4 Опционально можно настроить аутентификацию без пароля
not a tty
ssh-keygen
ssh-copy-id oracle@servername_1
После выполнения этих пунктов у пользователя oracle будет достаточно прав для создания интерфейса eth0:1 и назначения ему виртуального ip-адреса. Во время миграции сервера этот интерфейс будет создаваться с помощью скрипта wlsifconfig.sh, запущенного nodemanager-ом.
Интерфейс с VIP-адресом (в моём случае это 172.16.1.3) необходимо создать до того, как будет запущен сервер, слушающий на нём.
1.5 Создание интерфейса eth0:1 на первом хосте:
[oracle@servername_1 ~]sudo $DOMAIN_HOME/bin/server_migration/wlsifconfig.sh -addif eth0 172.16.1.3 255.255.240.0Здесь 172.16.1.3 - VIPадрес
255.255.240.0 - маска подсети.
Если скрипт отработает без ошибок, в выводе ifconfig появится новый интерфейс.
eth0 Link encap:Ethernet HWaddr 55:53:56:56:11:30Теперь можно обновить arp-таблицу на ближайшем свиче командой
inet addr:172.16.1.1 Bcast:172.16.15.255 Mask:255.255.240.0
[...]
eth0:1 Link encap:Ethernet HWaddr 5:53:56:56:11:30
inet addr:172.16.1.3 Bcast:172.16.15.255 Mask:255.255.240.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
sudo arping -q -U -c 5 -I eth0 172.16.1.3
2. Настройка Nodemanager.
К конфигурационный файл nodemanager.properties добавить строкиInterface=eth0В качестве ListenAddress указываются ip адреса хостов. В моём случае это 172.16.1.1 и 172.16.1.2 соответственно.
NetMask=255.255.240.0
UseMACBroadcast=true
ListenAddress=172.16.1.1
3. Настройки Weblogic сервера.
3.1. Необходимо создать кластер. В моём случае это trvlrCluster.
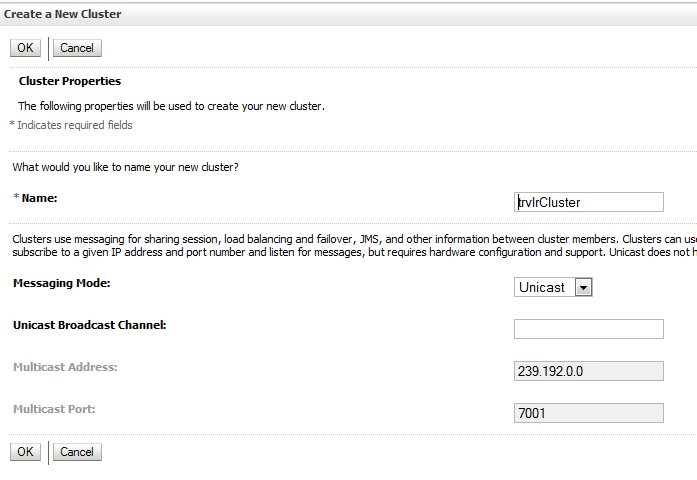
3.2. Создать две машины.

В настройках первой указать ip-адрес (hostname) и порт nodemanager-a первого хоста 172.16.1.1 (sms-a) Для второго - 172.16.1.2 (sms-b)

3.3. Создать два сервера. trvlr_1 и trvlr_2. Для первого серверa указать Listen Address - адрес виртуального интерфейса, созданного на шаге 1.5. В моём случае это 172.16.1.3. Для второго сервера - ip адрес второго хоста(172.16.1.2). Возможности мигрировать у второго сервера не будет.
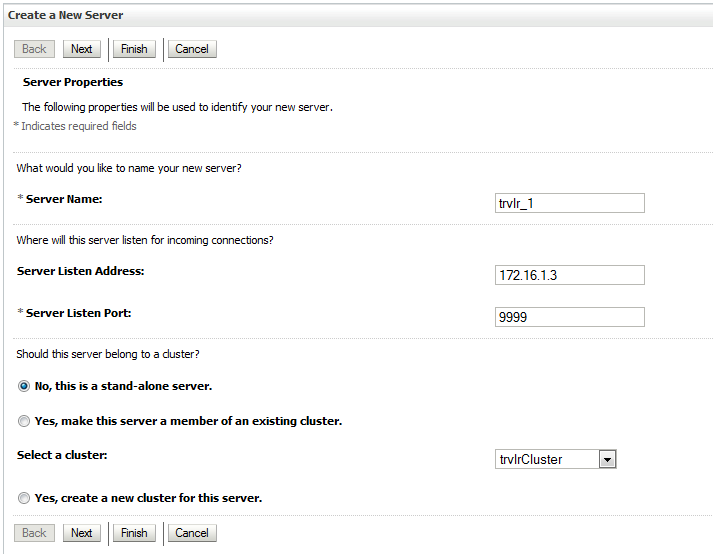





4. Проверка работоспособности.
4.1 На вкладке servers -> trvlr_1 -> Control -> Migration можно проверить возможность мигрировать на второй хост.
4.2 После того как сервер поднимется на втором хосте можно проверить автоматическую миграцию сервера. Для этого надо выключить host 172.16.1.2. Если возможности выключить хост нет, можно погасить на нём nodemanager, сервер trvlr_1 и интерфейс eth0:1
killall -f -9 weblogic.NodeManager
killall -f -9 trvlr_1
sudo $DOMAIN_HOME/bin/server_migration/wlsifconfig.sh -removeif eth0 172.16.1.3 255.255.240.0


{kind=link}
{kind=link}